Code
load("../data/X.Rdata")
load("../data/Y.Rdata")Chargement de l’environnement
Dans cette séance de travail pratique, nous avons comparé les résultats de méthodes non supervisées appliquées à un jeu de données correspondant à des poches de protéines. Le but étant de déterminer le druggabilité de ces poches en fonction de leur propriétés.
Chargement des données
load("../data/X.Rdata")
load("../data/Y.Rdata")Notre jeu de données contient 109 poches, chacune décrite par 18 descripteurs.
library(FactoMineR)
res.pca <- PCA(X, scale.unit = TRUE, graph = TRUE, ncp = 5)
# Visualisation des descripteurs
barplot(res.pca$eig[, 1:3], beside = TRUE)# Etude de l'espace des variables
plot(res.pca, choix = 'var')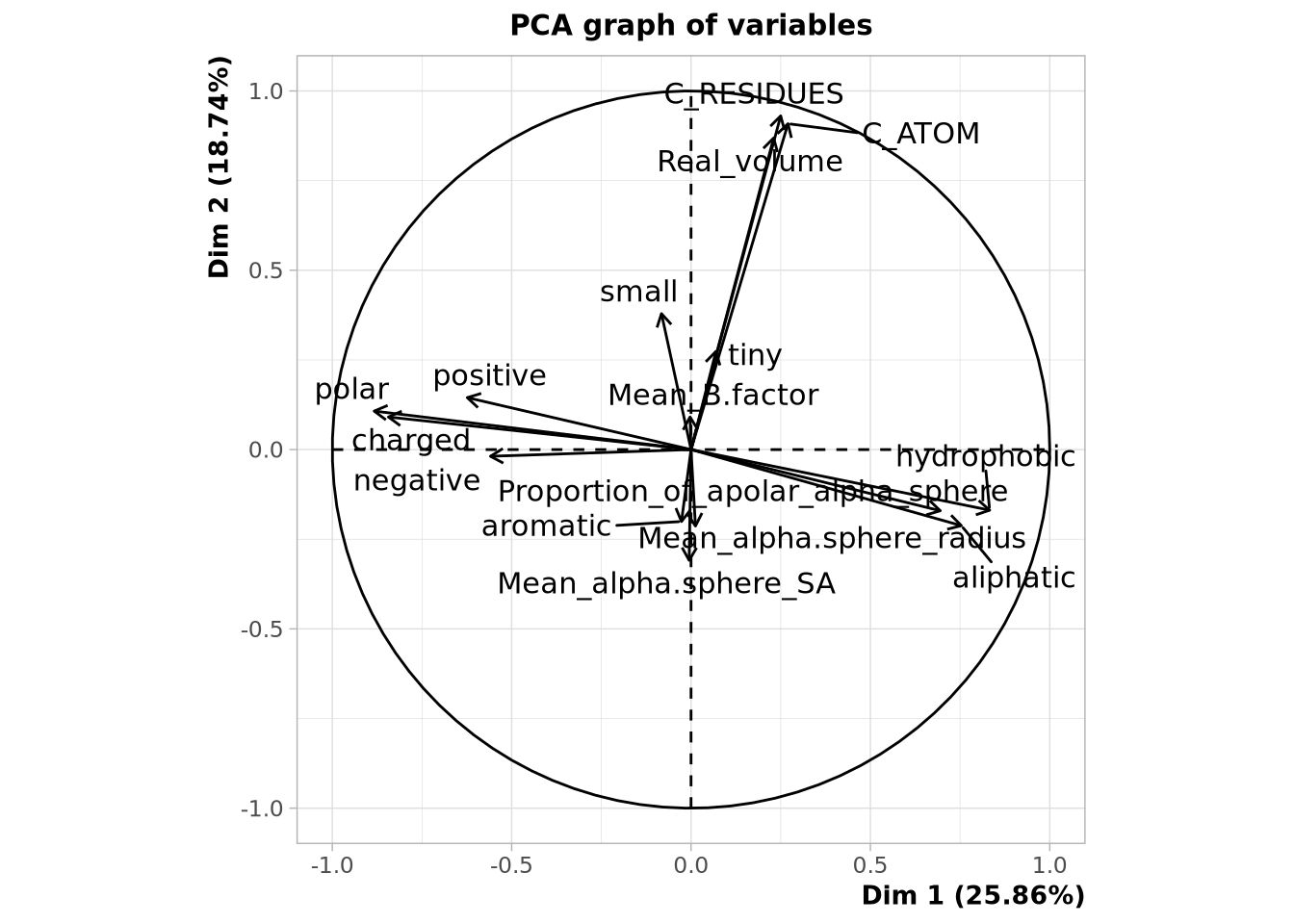
# Etude de l'espace des individus
plot(res.pca, choix = 'ind', label="none")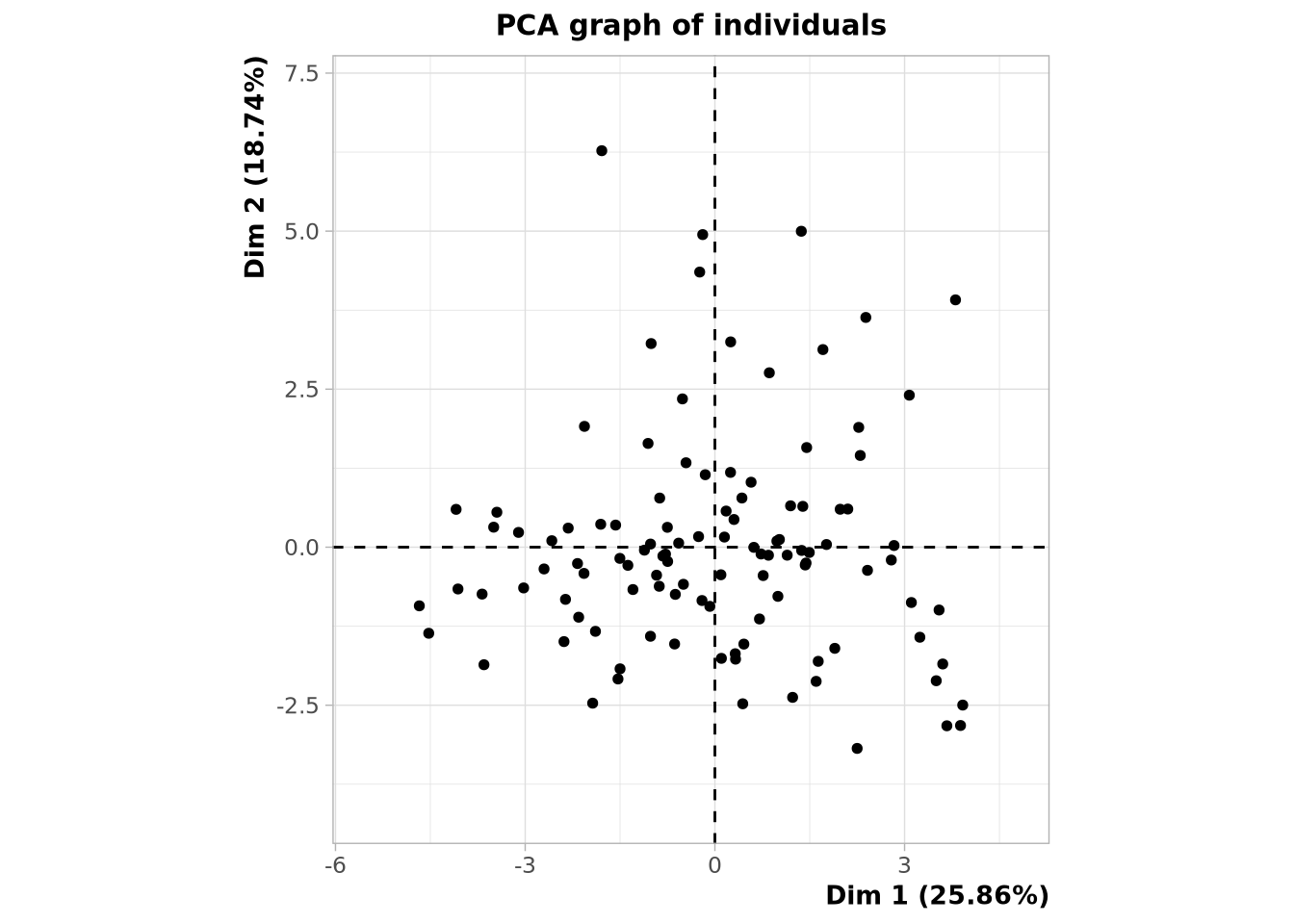
Nous observons que pour les données mises à l’échelle nous avons plusieurs valeurs propres des importances décroissante. Si nous observons le barplot des données non mises à l’échelle, nous n’avons qu’une seule valeur propre dont la valeur est très élevée. Si nous comparons les graphes des variables, nous voyons pour les données mises à l’échelle deux composantes principales expliquant respectivement 25,86% et 18,74% de descripteurs. Pour les données non mises à l’échelle nous voyons une première CP à 99,91%. Cela est dû à l’ordre de grandeur du volume réel qui est bien supérieur à celui des autres descripteurs.
Pour travailler sur la suite, nous allons donc utiliser les valeurs mises à l’échelle et nous choissons donc de travailler avec les trois premières composantes principales qui expliquent environ 60% des résultats.
Sur ce plan, nous avons 44,6% de variabilité ce qui implique que toute la variance du jeu de données n’est pas expliquée par ces deux vecteurs propres. Nous voyons qu’il y bien des variables mieux représentées que d’autres, elles correspondent à celles s’éloignant le plus de centre du graphe (ex: C_ATOM, polar, aliphatic) Les variables corrélées sont celles situées dans les mêmes régions par rapport à un axe et les anti-corrélées sont celles dans les régions opposées par rapport à un axe. Les variables “indépendantes” sont celles n’étant pas expliquées par les deux axes. Nous n’avons pas d’information sur elles et ne peuvent donc pas être comparées aux autres. Nous avons donc un premier axe qui caractérise la polarité
Il y bien des outliers, points isolés du reste. Pour les proches au centre de la projection sont celles étant mal expliquées par nos deux composantes principales.
plot(res.pca, choix = 'ind', select = poches, axes = c(3,4))Warning: ggrepel: 3 unlabeled data points (too many overlaps). Consider
increasing max.overlaps
library(corrplot)corrplot 0.92 loadedcorrplot(cor(X), tl.cex = 0.7)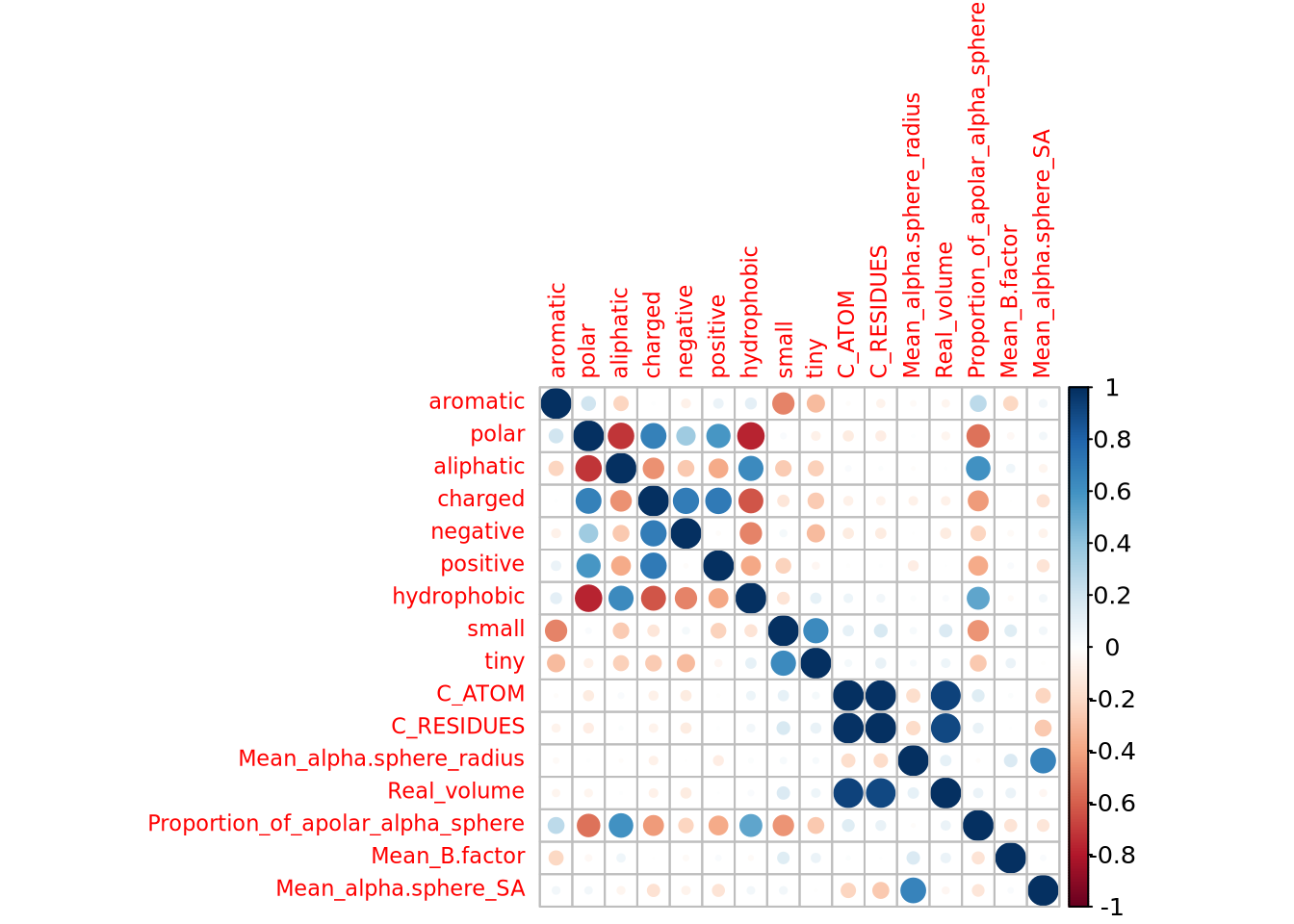
library(ggplot2)
library(factoextra)Welcome! Want to learn more? See two factoextra-related books at https://goo.gl/ve3WBafviz_pca_biplot(res.pca, label="var", repel = TRUE)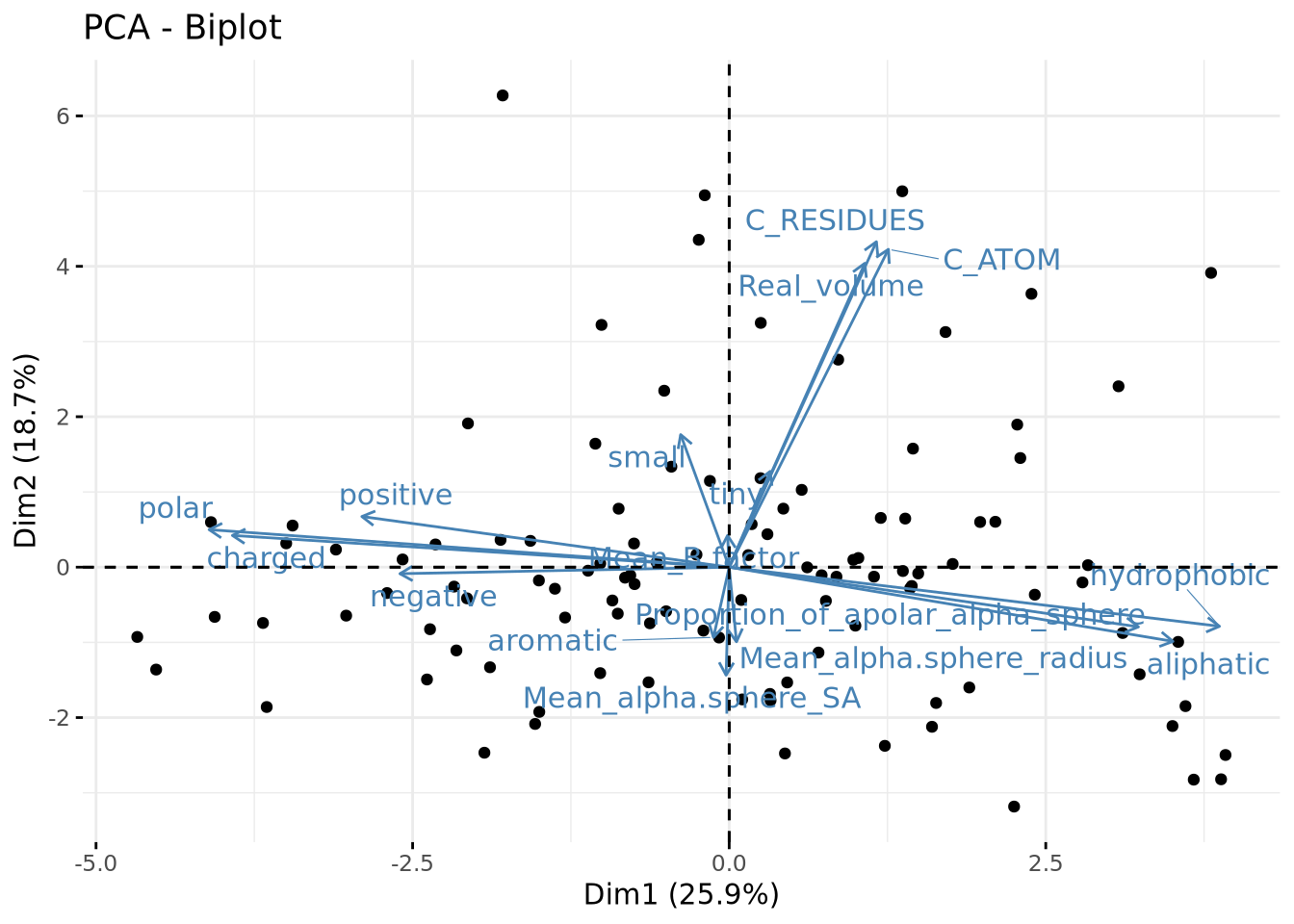
train.names <- sample(rownames(X), 2*nrow(X)/3, replace = FALSE)
test.names <- rownames(X)[-which(rownames(X) %in% train.names)]res.sample <- PCA(X, scale.unit = TRUE, ind.sup = match(test.names, rownames(X)))
fviz_pca_biplot(res.sample, geom='point')train.set <- X[train.names,]
test.set <- X[test.names,]
train.dtf <- cbind(train.set, Y[train.names,])
test.dtf <- cbind(test.set, Y[test.names,])# res.cutree <- cutree(x_classif, k=4)
# clust_colors <- c("red", "blue", "green", "yellow")
# fviz_pca_biplot(res.pca, col.ind = res.cutree, label = "var", choix = "ind")@online{bari garnier2024,
author = {Bari Garnier, Martin},
title = {Principal {Component} {Analysis}},
date = {2024-01-24},
url = {https://MartinBaGar.github.io/Master_ISDD_fiches//mda/pages/tp2.html},
langid = {en}
}